KesGPT-Image-2图片研究论文图示
GPT-Image-2 案例 · LLM 预训练数据混合桑基图
来自“研究论文图示”精选展示的 GPT-Image-2 参考案例,适合检索“LLM 预训练数据混合桑基图”方向的生成效果。
Hasil
Latar Kes
来自 GPT-Image2-Skill README 的精选展示条目,适合作为“研究论文图示 / LLM 预训练数据混合桑基图”方向的站内参考案例。
Kandungan Prompt
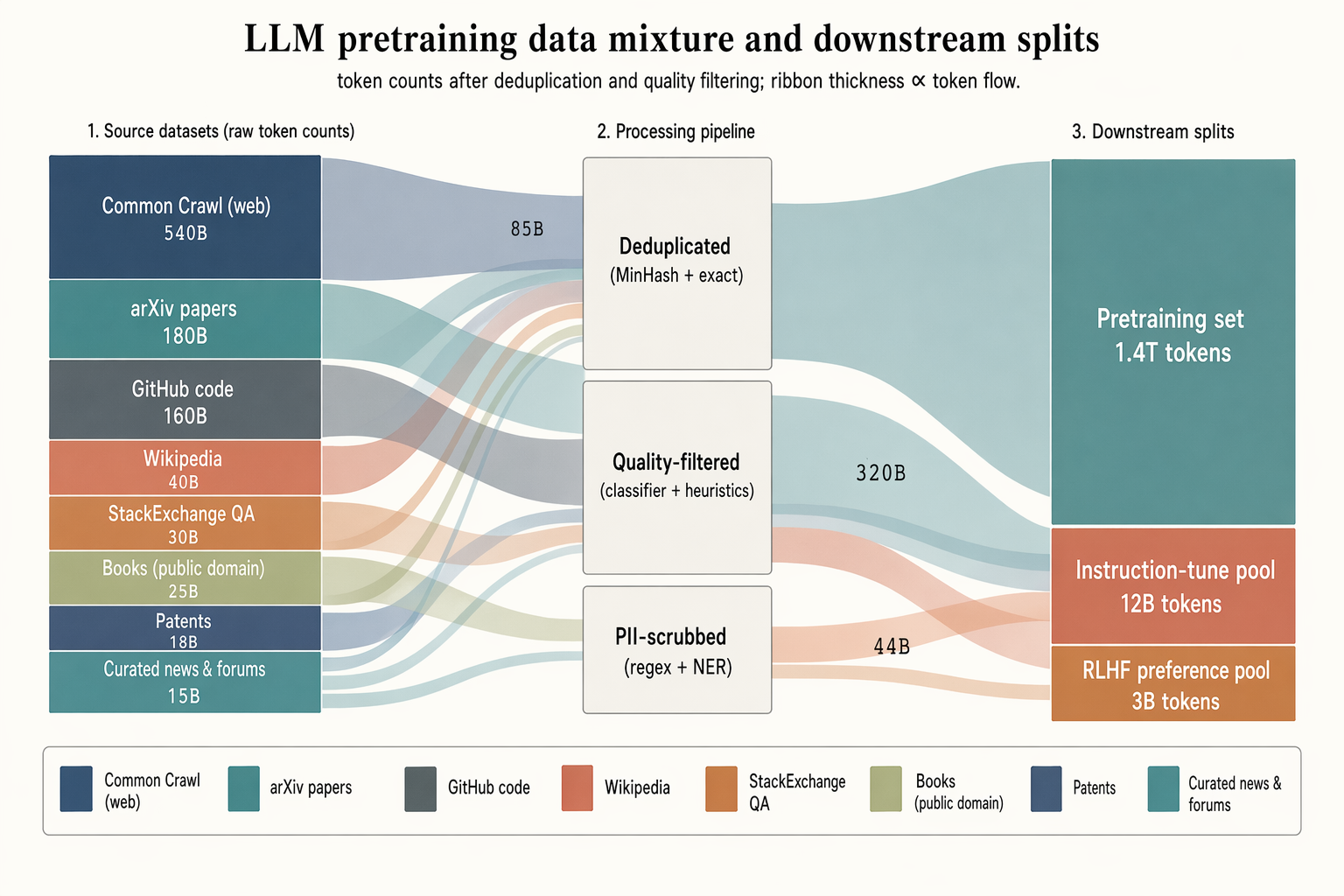
横向 16:9 桑基图,展示预训练数据混合,三阶段带透明色带。 左侧(8 个源块,高度按标记数比例):"Common Crawl (web) 540B"(柔和海军蓝,最大)、"arXiv papers 180B"(尘土绿松石)、"GitHub code 160B"(石板灰)、"Wikipedia 40B"(柔和陶土色)、"StackExchange QA 30B"(暖铜色)、"Books (public domain) 25B"(浅橄榄色)、"Patents 18B"(浅海军蓝)、"Curated news & forums 15B"(尘土绿松石)。 中间(3 个处理块,堆叠):"Deduplicated (MinHash + exact)"、"Quality-filtered (classifier + heuristics)"、"PII-scrubbed (regex + NER)"。 右侧(3 个最终拆分):"Pretraining set 1.4T tokens"(最大)、"Instruction-tune pool 12B tokens"、"RLHF preference pool 3B tokens"。 流动色带继承源颜色,中间标签显示令牌数("85B"、"320B"、"44B")。底部带图例条。 标题:"LLM pretraining data mixture and downstream splits"。副标题:"去重及质量过滤后的标记数;色带厚度 ∝ 标记流量"。
Catatan Hasil
这个案例已从 GPT-Image2-Skill README 迁入 AIPlusLab `/prompts`,方便在站内直接检索、浏览和复用。
ModelGPT-Image-2
Kategori图片
JenisKes
Sumberopenai